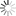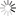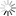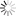新闻网讯 近日,第70届国际电子器件会议(IEDM)会议在美国旧金山召开。该会议是全球最具影响力的半导体器件领域学术会议,议题涉及半导体材料与器件、器件制造工艺、集成电路技术与应用等领域。我校集成电路学院缪向水、李祎团队在会议上报告了团队在存算一体技术方面的最新研究成果“Demonstration of a Floating-point Deep Neural Matrix Equation Solver using 3D Vertical ReRAM with High Energy- and Area-Efficiency”。
我校这一成果实现了国际上首个基于三维集成阻变存储器阵列的浮点精度存算一体系统,为实现高能效、高精度的AI-for-Science计算应用提供了重要方案。我校集成电路学院2019级博士生李健聪(已毕业入站从事博士后研究)和2020级博士生任升广为论文共同第一作者,李祎教授、何毓辉教授和缪向水教授为论文共同通讯作者。我校是论文唯一完成单位。
求解矩阵方程Ax=b是科学计算和具身智能等领域的基础数学问题,核心在于对方程系数矩阵A进行求逆运算。近年来,AI-for-Science相关研究表明神经网络方法能够突破传统矩阵分解方法在时间复杂度上的瓶颈,实现高效的矩阵求逆计算。但是,传统冯·诺依曼架构的计算机系统在神经网络的训练和推理过程中,面临算力不足和硬件资源消耗过大的挑战(图1)。基于阻变存储器的存算一体技术被视为高效加速神经网络计算的潜力方案。然而,求解矩阵方程通常需要浮点计算以满足精度需求,而忆阻器阵列的擦写开销及低精度模拟计算机制成为制约存算一体技术实现浮点神经网络训推性能的关键瓶颈。此外,如何突破当前平面集成阵列的算力与能效极限是另一重要难题。
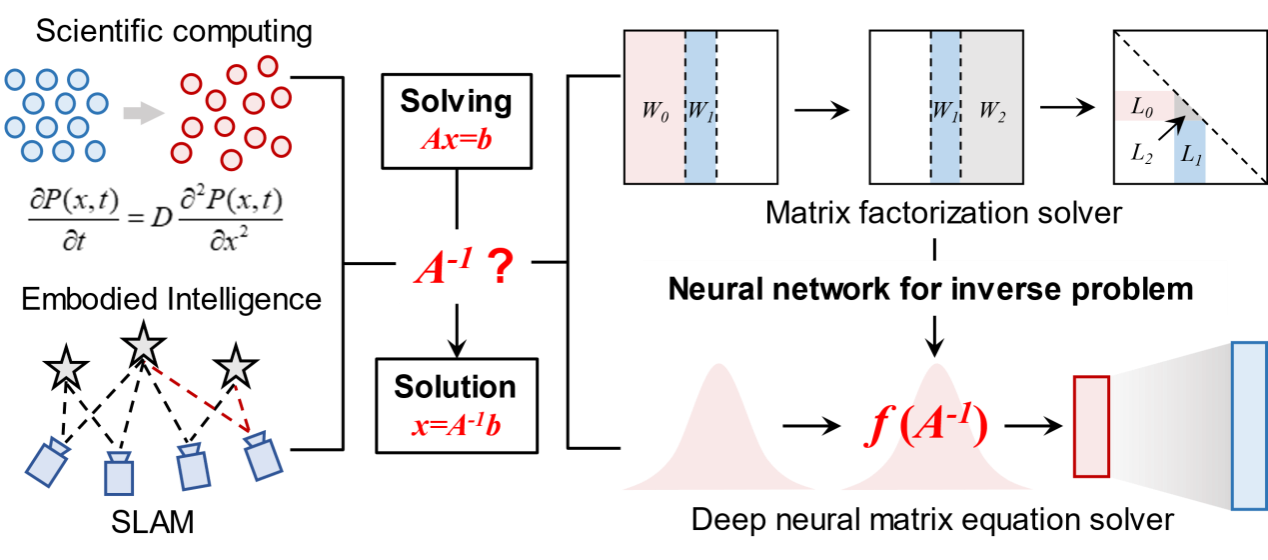
图1. 研究思路:基于神经网络逆运算的矩阵方程求解器
针对上述问题,我校团队构建了一套基于三维垂直堆叠的阻变存储器阵列(3D-V ReRAM)的存算一体神经网络训推软硬件系统,可以高效执行系数矩阵A的浮点精度逆运算及方程的浮点精度求解,并取得了系列进展。
在三维集成层面,团队设计并制备了4Kb规模、4层堆叠的高一致性高可靠性3D-V ReRAM阵列。阵列在操作功耗(16.4fJ)、擦写延时 (100ns) 、单片可扩展性(>493Mb)和多值编程特性(2-bit)等多方面指标均达到了国际先进水平,为实现高能效存算一体系统提供了硬件基础(图2)。
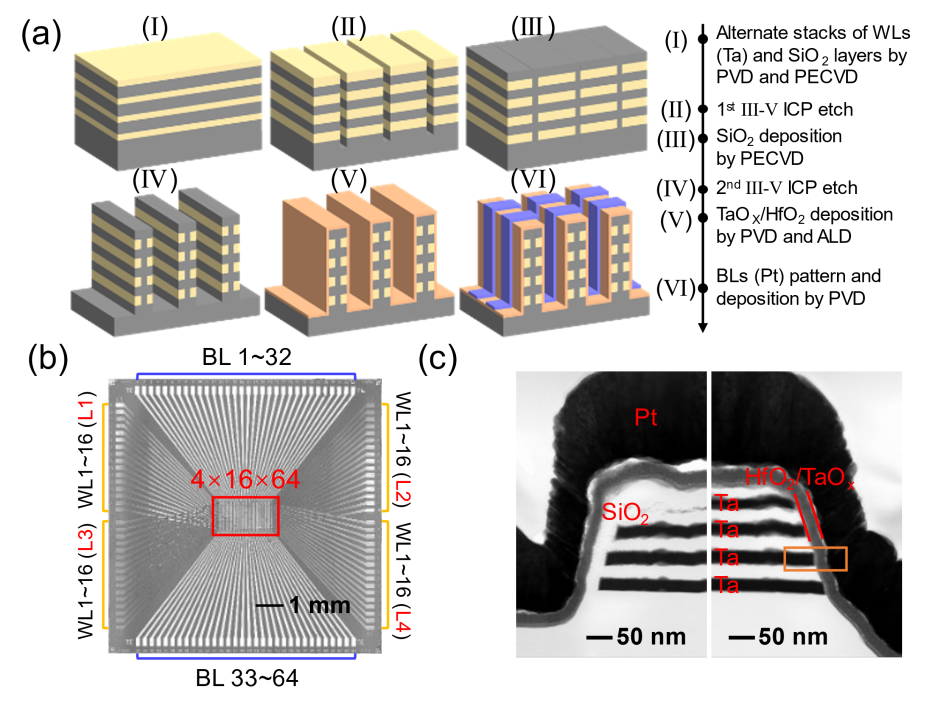
图2. 4 Kb三维集成阻变存储器阵列
在计算架构及电路层面,针对网络高精度低开销训推这一关键挑战,团队提出了阻变器件本征随机性驱动的混合精度训练架构,实现了神经网络求解器的高效求逆。同时,为支持方程的高精度求解,将3D-V ReRAM阵列与任意精度存算一体技术(Arbitrary-Precision Computing-in-Memory, ArPCIM)结合,构建了支持原位单精度浮点计算的存算一体单元,突破了低精度器件实现浮点精度计算的难题(图3)。
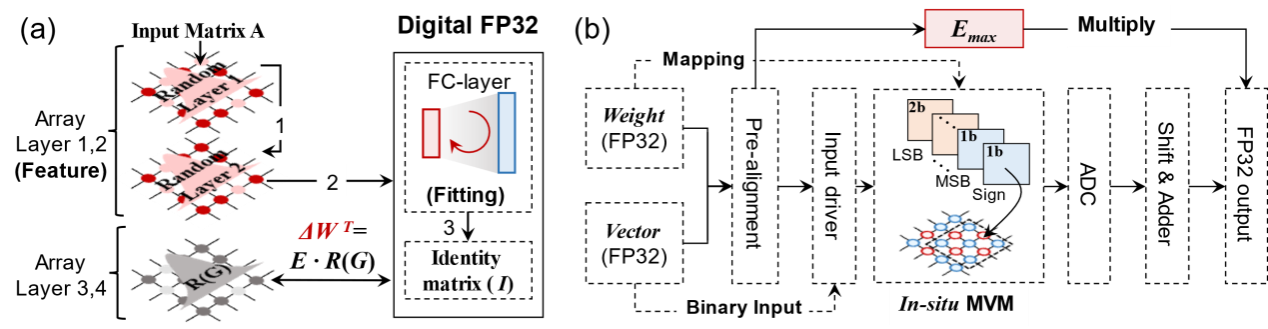
图3. 神经网络求解器的混合精度训练框架及原位浮点计算架构
团队所构建的存算一体原型系统实验演示了阵列中的原位FP32精度矩阵乘法计算,一维对流扩散方程的高精度求解计算误差低于10-13,相当于双精度浮点求解系统。性能评估结果表明,在22nm节点工艺下,上述系统预期可实现11.5 TFLOPS/W的 FP32精度计算能效和大于0.63 TFLOPS/mm2的单位面积算力,相对当前最先进的NIVIDA H100 GPU可实现132倍的能效提升和7.6倍的面积效率提升(图4)。

图4.存算一体系统及浮点计算任务评估
本论文是继忆阻稀疏矩阵方程求解器(Sci. Adv. 2023)、快速欠定矩阵方程求解器(IEDM 2023)、任意精度存算一体加速器(IEEE TCASI 2024)之后,我校团队在存算一体技术方向取得的又一新突破。上述研究工作得到了国家科技创新2030重大研究计划、国家重点研发计划、我校基础研究支持计划等项目的资助,以及国家集成电路产教融合创新平台、先进存储器湖北省重点实验室等平台的支持。